模型记忆原理
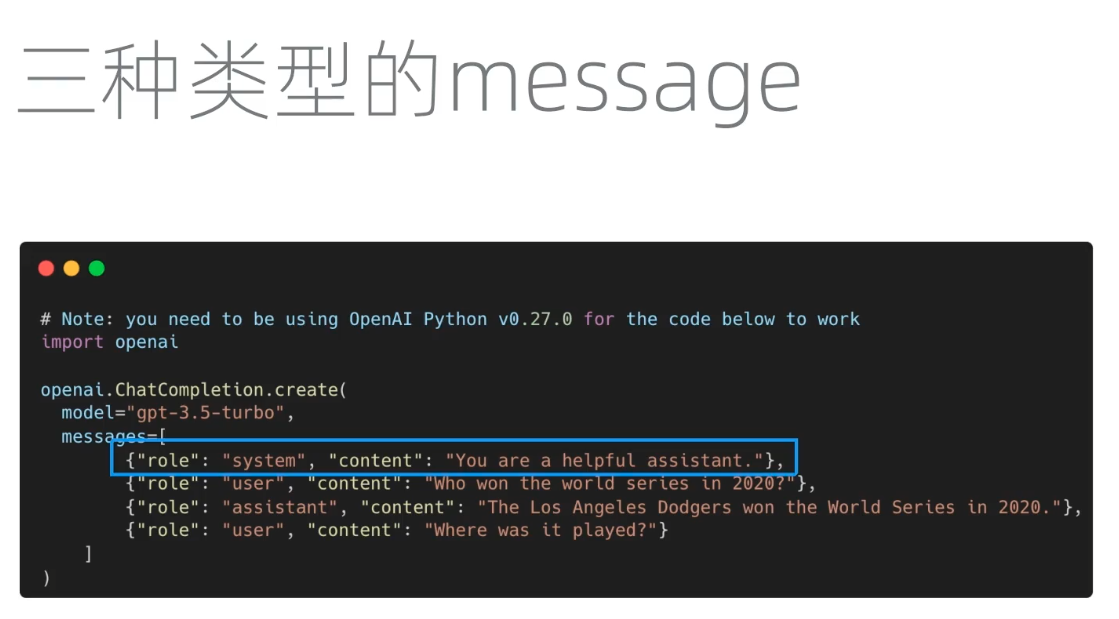
用户每次提交给 GPT 内容里面的三部分内容构成:
-
第一部分: System 内容(系统提示词),对话应用后台设置的长期身份设定文字,用户也可以自定义设置系统提示词,比如:你是一个有用的助手。
-
第二部分:User 内容(用户提示词),就是用户输入的提问内容。 开始对话:你第一次提问时对话应用会把上面的 System+User 两个内容发给 GPT 模型,然后 GPT 模型根据这两个System+User 内容推理计算出反馈内容发送给用户。
-
第三部分:GPT 模型发送给用户这个反馈内容就是 Assistant Content 内容(助理提示词),这就是在后面继续对话会用到的第三部分内容,以帮助 GPT 模型记忆本次对话的历史。 继续对话,多轮对话时,对话应用会把之前的所有 System,User,Assistant 内容加上新的 User 内容(用户新输入的提示词)一起发给 GPT 模型,不断对话下来你提交给 GPT 模型的内容会越来越多,System,user,assistant,user,assistant,user...
为了让 GPT 模型记住历史对话,对话应用需要一直重复提交前面累积的内容。这时候后续对话使用的 token 数量会越来越多(Open AI Token:内容长度的单位),直到达到 max token 限制以及模型上下文限制。
对话须知
-
GPT 模型没有记忆,对话过程表面上看是有上下文,每次 GPT 模型都进行了重新推理。真正记忆上下文的是本地电脑(浏览器或者对话应用客户端),并在每次对话中向 GPT 模型提交。
-
常见限制:gpt-3.5-turbo 上下文长度为 8K。
-
如果对话内容长度较大时,用户应设置较大的 max token 值,并使用上下文长度较大的 GPT 模型:gpt-3.5-turbo-16k上下文长度为 16K,gpt-4-32k上下文长度为 32K。