采样温度(Top P)
什么是采样温度(Top P)?
使用采样温度(Top P)时模型仅考虑具有最高概率质量(由top_p参数确定)的标记(token)。还有其它替代采样温度(Top P)的参数方法,例如:核心采样。
例如,值 0.1 表示仅考虑概率质量前 10% 的标记(token)。
OpenAI 通常建议使用采样温度(Top P)或核心采样进行模型设置,但不能同时使用两者。
用户可以在设置页面中调整 GPT 平台的采样温度(Top P)值,如下所示。
调整采样温度(Top P)设置
平台默认采样温度(Top P)值为 0.01。
用户可以从“GPT 模型”选项卡的采样温度(Top P)字段中进行更改。
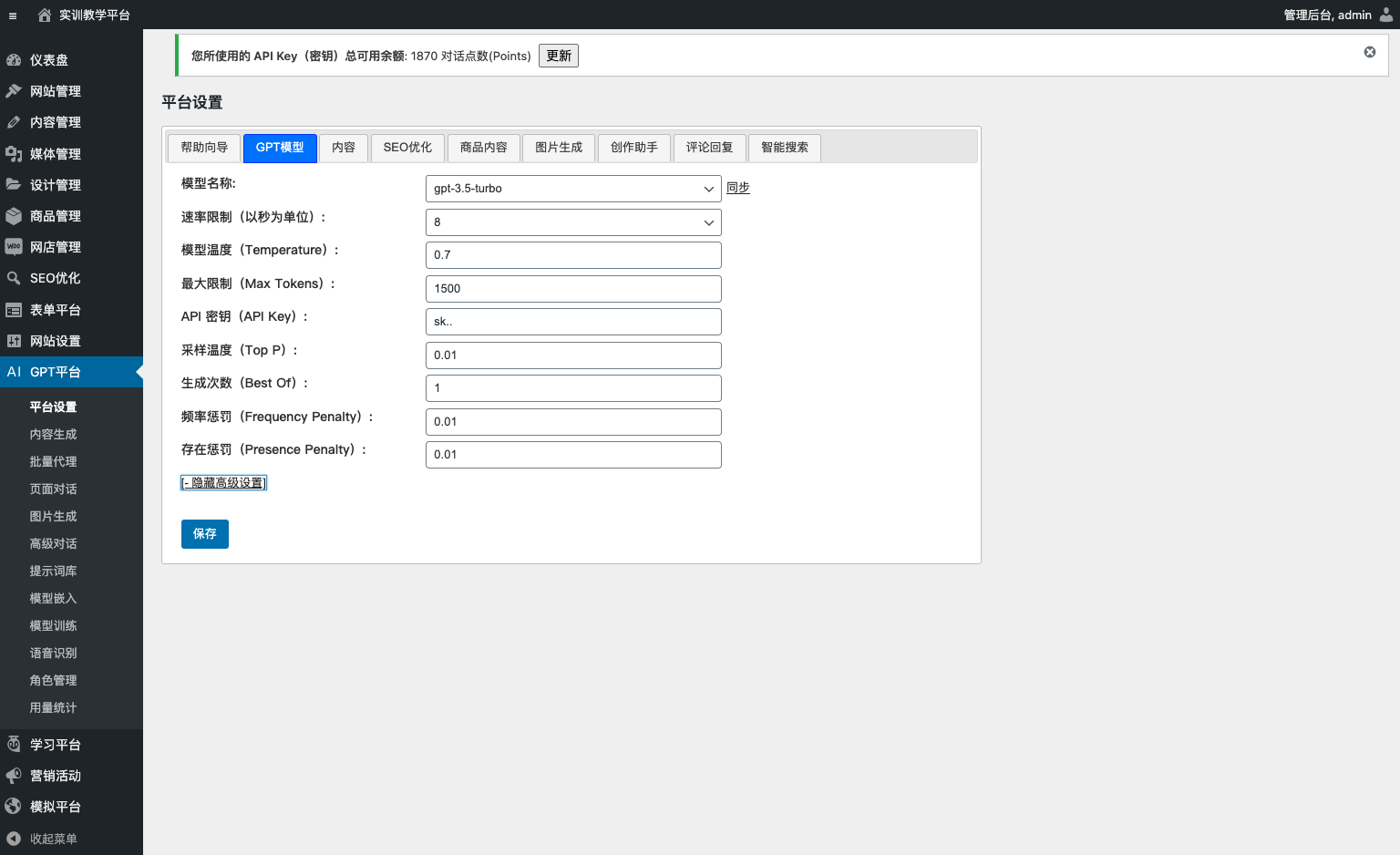
修改步骤:
- 单击“设置”页面,然后查找“GPT 模型”选项卡。
- 在采样温度(Top P)字段中输入新值。
- 单击“保存”按钮以保存更改。
平衡 GPT 模型文本生成的多样性
采样温度(Top P)参数是 GPT 生成的文本多样性的控制参数。
使用 GPT 生成文本时,模型会为生成的文本中的每个单词生成词汇表的概率分布。
采样温度(Top P)参数控制选择要包含在生成文本中的概率最高的单词。
具体来说,它设置了一个阈值,以便仅包含概率大于或等于阈值的单词。
阈值是通过取概率最高的单词的前 P 百分比来计算的。
例如,如果采样温度(Top P) top_p=0.9,则阈值设置为概率最高的单词的第 90 个百分位数中的单词的概率。
采样温度(Top P)的值可以设置为 0 到 1 之间,其中较低的值将导致生成的文本更加多样化,较高的值将导致更多重复或“安全”的文本。
- 较低的值: 更多样化的生成文本。
- 较高的值: 更多重复或“安全”的文本。
当您增加采样温度(Top P)时,模型将倾向于生成更保守的文本,因为使用概率阈值时,将考虑最可能的结果,从而导致多样性降低。
此外,使用较高的采样温度(Top P)参数,模型可能不会在生成新文本时承担任何风险,而是倾向于选择更常见/重复的单词。
另一方面,在采样温度(Top P)参数较低的情况下,模型将倾向于生成更多样化的文本,并且可能会通过选择可能性较小的单词来承担风险。然而,这也可能增加产生无意义或无意义的句子的风险。
总之,采样温度(Top P)参数允许控制模型在生成文本时愿意承担的“风险”级别。值越高,模型将倾向于生成更多重复的文本,而值越低,模型将倾向于生成更多样化的文本。